A storyboard says what is in the show. An animatic says how long the show is. Skip this step and you find out only at the colour-grade — which is too late.
01The problem
Animatics are where pacing problems become visible. The trouble is they've historically been expensive: a sound editor cuts dialogue to picture, an assistant edits the panels to the dialogue, a director gives notes, the loop repeats. Three days minimum, and that's before the music demo arrives.
AI tools made the bottleneck worse, not better. Voice clones are now trivial; aligning them to a board still wasn't. Most teams ended up with a folder of WAV files and a Premiere project nobody but one person could open.
02The approach
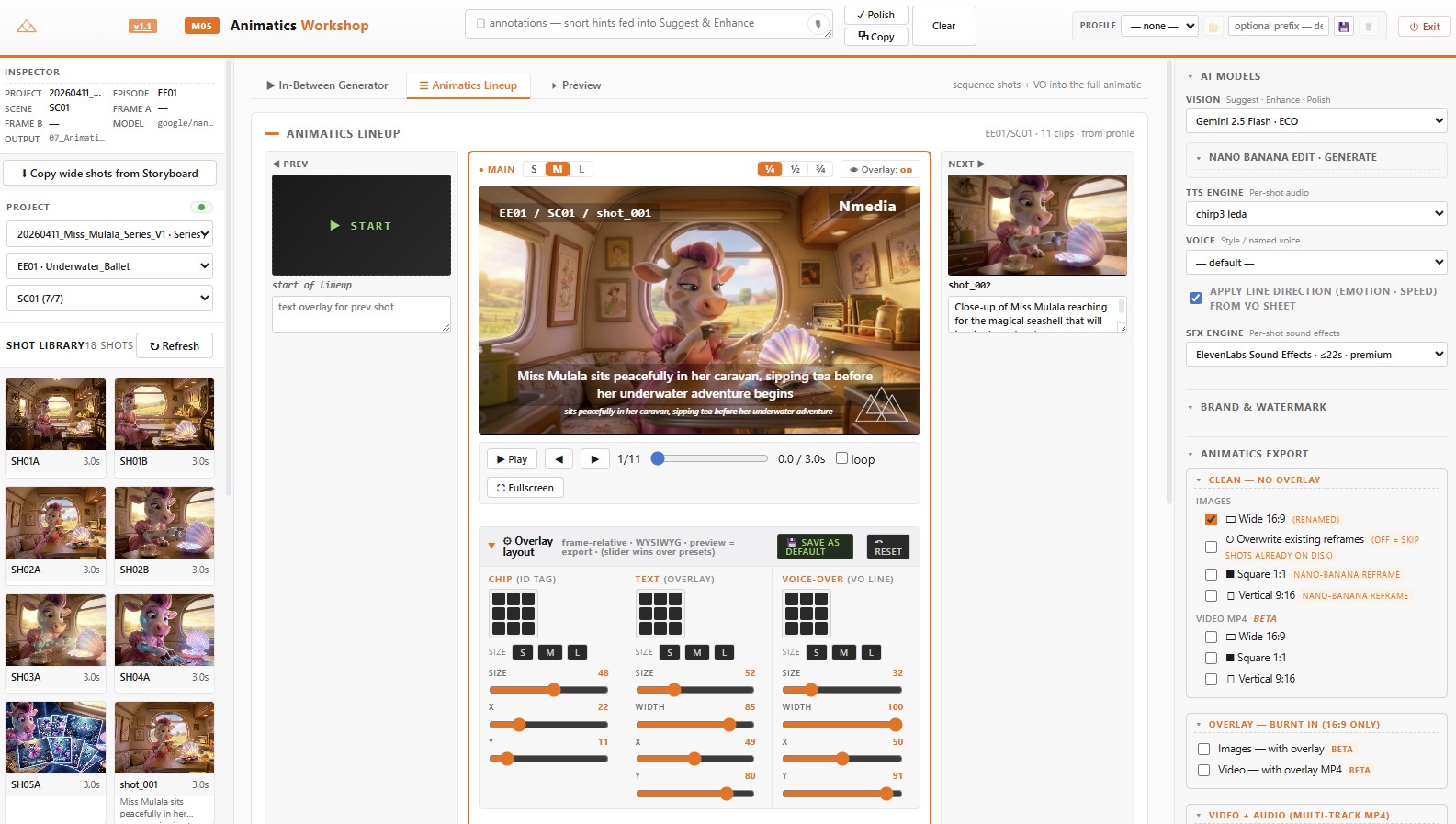
Module 05 ingests the boards from Module 04 plus the voiceover script extracted by Module 02. It synthesises voice with a self-hosted TTS (we use IndexTTS-2 for zero-shot voice cloning) and auto-aligns each line to its corresponding board panel. The first cut is generated, not edited.
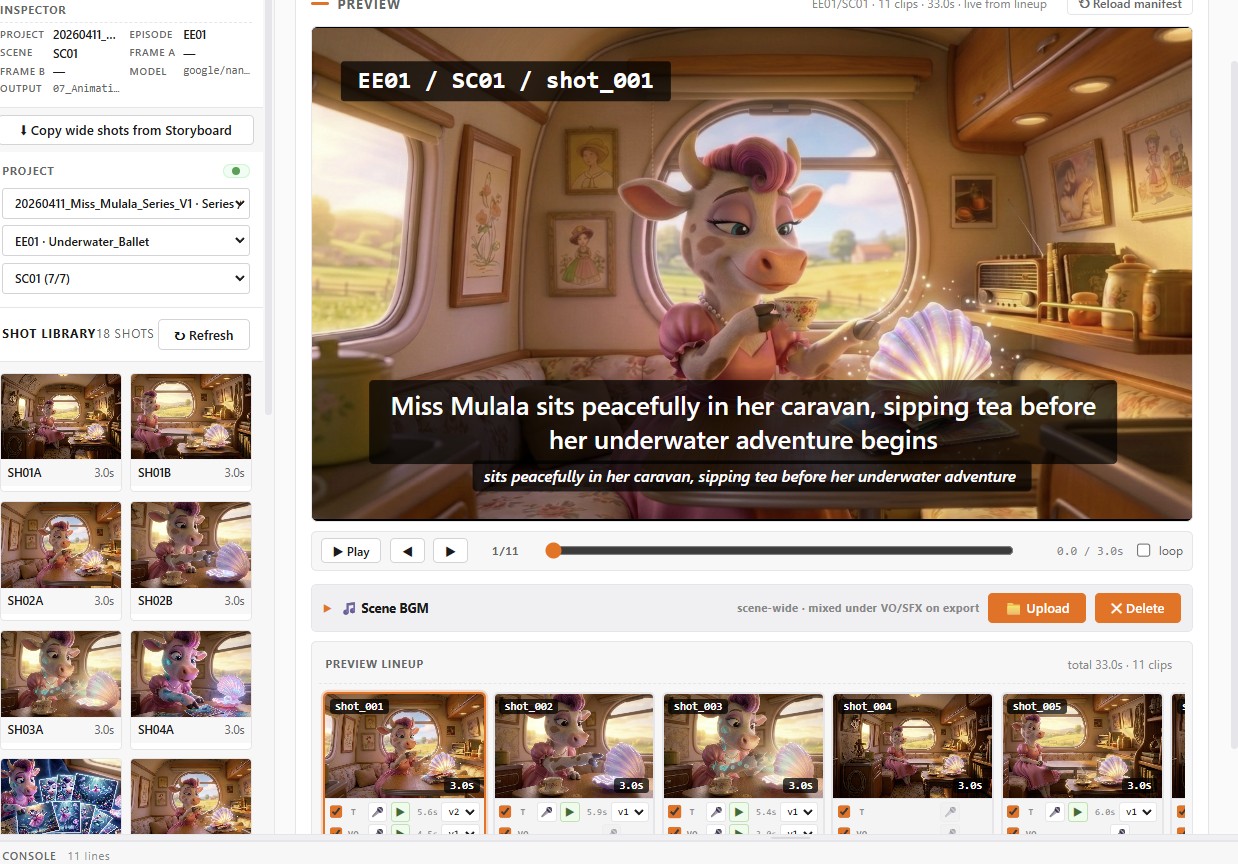
From there the panel becomes a re-cut surface: drag a panel boundary to extend a beat, swap a voice take, scrub a music bed under it. The output is an MP4 plus a structured EDL that downstream tools can read — so when Module 06 (Animation Sandbox) takes over, it inherits the timing instead of guessing it.
"The first cut is free. Every cut after that is faster than opening Premiere."
03Inside the control panel
The workshop is a single timeline view with three lanes. Boards on top, voice in the middle, music underneath. Everything is editable in place.
- Voice clone routing. Each character ID in the script maps to a voice profile. Re-roll a single line without disturbing the rest.
- Auto-alignment. First-cut panel timings are derived from the dialogue duration plus a configurable per-show pacing curve.
- Music bed slot. Drop in a placeholder music track now, replace with the licensed mix later — timing data survives the swap.
- Board edit round-trip. Spot a panel that's wrong? Edit it in Module 04 and the animatic re-imports without losing your timing edits.
04What's next
The next iteration adds multi-take voiceover comparison — generate three reads of every line, audition them inside the timeline, lock the best one. After that: shot-level action timing, so the animatic can suggest motion durations the animation module then honours by default.